-
Bug
-
Resolution: Fixed
-
 Minor
Minor
Since some weeks ago we are experimenting some problems with the jenkins queue.
While looking for dupes before creating this... I've found a bunch of issues, similar, but I'm not sure if any of them are the very same issue than this, because they often comment about various plugins we are not using at all). Here it's a brief list of those "similar" issues, just in case, at the end, all them are the same problem: JENKINS-28532, JENKINS-28887, JENKINS-28136, JENKINS-28376, JENKINS-28690...
One thing in common for all them is that they are really recent and it seems to be common that, whatever the problem is, it started around 1.611. While I don't have the exact version for our case (coz we update continuously) I'd say it started happening also recently here.
Description:
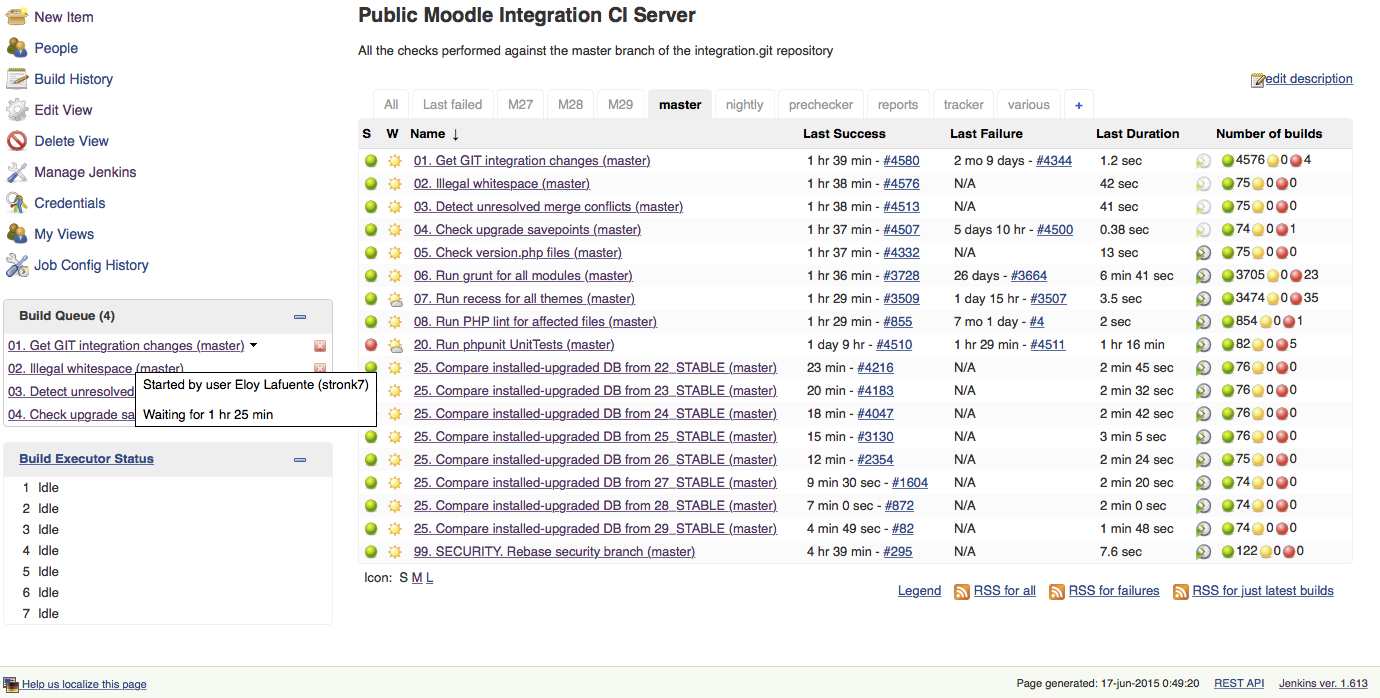
We have 2 jenkins server, a public one (linux) and a private/testing (mac) one. And we are experimenting the same problem in both. This is the URL of the public one:
There we have some "chains" of free-form jobs, with all the jobs having both the "Block build when upstream project is building" and "Block build when downstream project is building" settings ticked.
The first job is always a git-pull-changes one and it starts the "chain" whenever changes are detected in the target branch. We have one chain for every supported branch.
And this has been working since ages ago (years). If for any reason a job was manually launched or the scheduled (every 5 minutes) git job detected new changes... it never has been a problem. Those new jobs were there, in the queue, waiting for the current "chain" to finish. And, once finished, the queue handling was clever enough to detect the 1st job to execute from it, also deleting dupes or whatever was needed.
Basically, the summary is that it never became stuck, no matter how new jobs were in the queue or how they had landed to it (manually or automatically). So far, perfect.
But, since some versions ago.. that has changed drastically. Now, if we add manually jobs to the queue, of if multiple changes are detected in a short period of time... those jobs in the queue correctly wait for the current "chain" to end (like they used to do, can be viewed hovering over elements). But once the chain has ended, the queue is not able to decide any job to start with, and it became "locked" forever.
Right now, if you go to the server above... you'll see that there are 4 jobs, all them belonging to the "master" view/branch/chain, awaiting in the queue... never launched and, worse, preventing new runs in that branch to happen. And the hover information does not show any waiting cause (screenshots added, showing both manually added jobs when the chain was running and automatic jobs, any of them with a reason for the locking, as far as all the executors are idle).
And those self-locks are really having an impact here, because it's transforming our "continuous automatic integration" experience into a "wow, we have not run tests for master since 2 days ago, wtf, let's kill the queue manually and process all changes together, grrr" thing. Sure you get it, lol.
Those servers and chains have been working perfectly since the night of the times and, while we are using various plugins for notification, conditional builds and so on, it seems that the way the queue handles jobs using the core "Block build..." settings has changed recently, leading easily (both manually & automated changes) to some horrible locks.
Constantly. And it's a recent "change of behavior". I'm not sure if it's ok to call it a "bug" (although I feel inclined to think that), but can ensure that it's hurting our integration experience here.
Finally, we are reproducing this behavior with both 1.617 (testing server) and older 1.613 (public server).
Ciao and thanks for all the hard work, you rock ![]()

- is duplicated by
-
-
- Resolved
-
- is related to
-
-

- Resolved
-
