-
Bug
-
Resolution: Fixed
-
 Minor
Minor
-
None
-
Jenkins 1.654
Ubuntu Linux
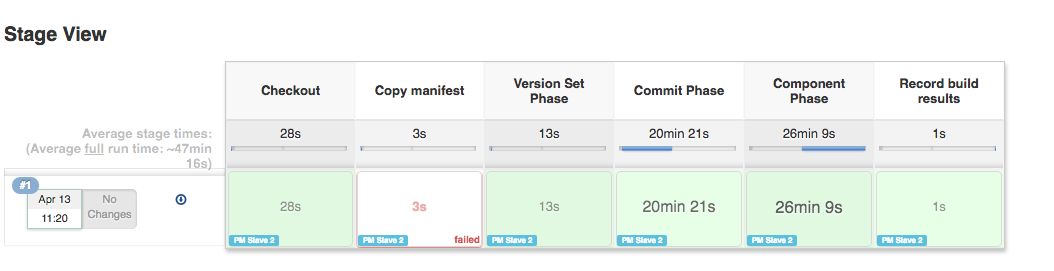
I have a stage with a try/catch block. It attempts to copy an artifact from a previous build. If it can't, the step throws an exception which is caught and handled. In the catch block it copies it from a different location (successfully) and my pipeline continues. However, in visualization, the stage is marked as failed. I would expect that regardless of exceptions thrown, if the stage completes successfully it should be green in visualization.
This is the error that is thrown/caught:
hudson.AbortException: Unable to find project for artifact copy: null This may be due to incorrect project name or permission settings; see help for project name in job configuration.
- is duplicated by
-
-
- Closed
-
- is related to
-
JENKINS-26522 Annotated block/stage status
-

- Closed
-
