-
Bug
-
Resolution: Unresolved
-
 Minor
Minor
-
None
-
Jenkins 1.642.4
Job DSL plugin v1.42
We have several Jenkins jobs which do nothing more than execute a single build step for running job DSL code. Further, some of these scripts are responsible for dynamically generating hundreds of new jobs. Now, sometimes these scripts run through to completion quickly (ie: 60 seconds or less) but other times they take severely long periods of time to complete (ie: 20-30 minutes or more).
Based on some crude investigations on my part trolling through build logs and poking around at the source code for the job DSL plugin, what I think it happening is that after the job DSL gets processed a list of newly generated and / or modified job configs are stored in memory and then the Jenkins master is 'scheduled' to run each of the individual job operations whenever it can. In these extreme situations it appears to take a very long period of time for all of these individual job operations (for which there are hundreds) to get scheduled and run. For example, when looking at the time stamps of specific log messages on the master we see it may be as much as 60 seconds from when one job update operation completes and the next one begins, with other unrelated output from the master in between.
Why this happens exactly, I am not sure. The conditions causing the slowdown are difficult at best to reproduce. I can say that in our production environment the Jenkins master runs on a virtual machine with considerable resources assigned to it, and we don't have any executors configured on the master so any load it may see is 100% associated with the master processes and not some unpredictable build operation.
If anyone can shed some light on why this behaves as it does, and whether there's anything we can do on our end to try and mitigate the issue that would be awesome. Also, it would be nice to see some sort of implementation change in the plugin itself to try and ensure the performance from the generation process is kept consistent between runs (ie: if all job configuration updates could be scheduled as a single larger operation instead of many smaller ones)
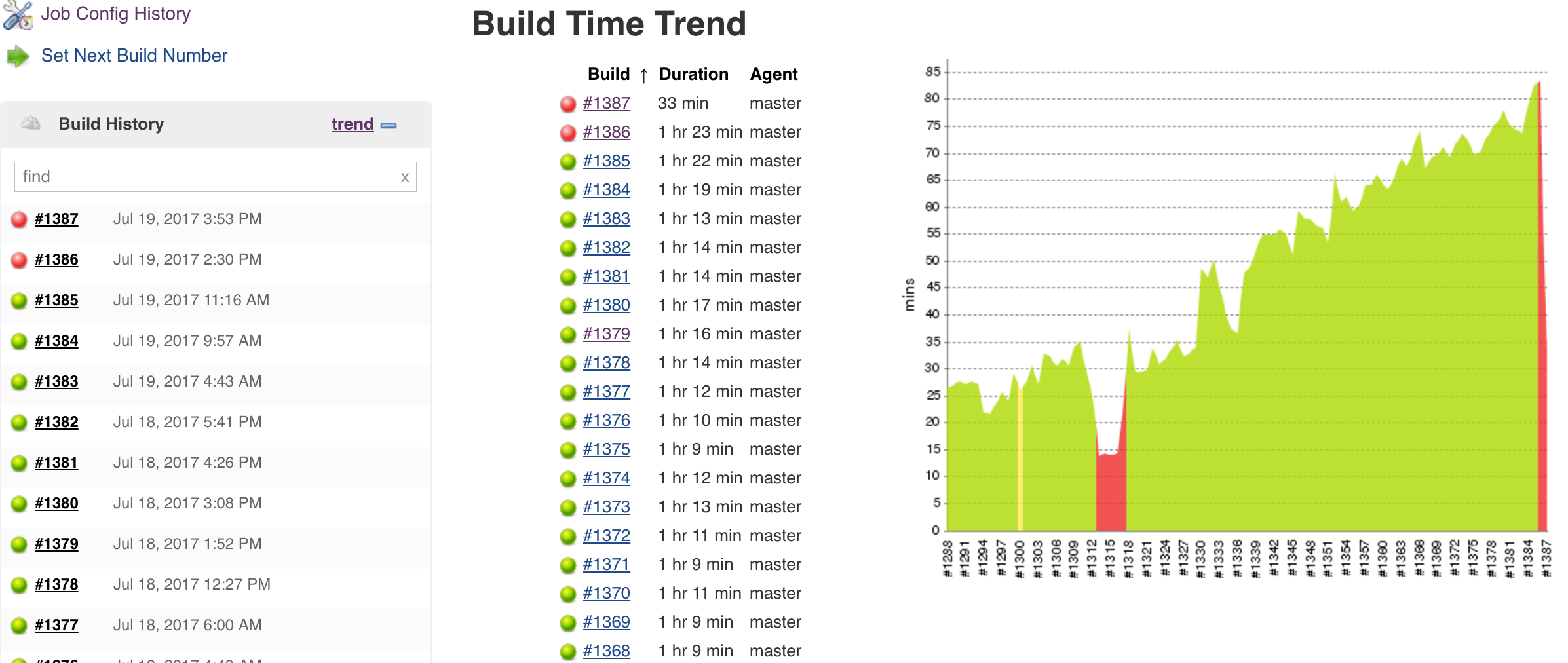
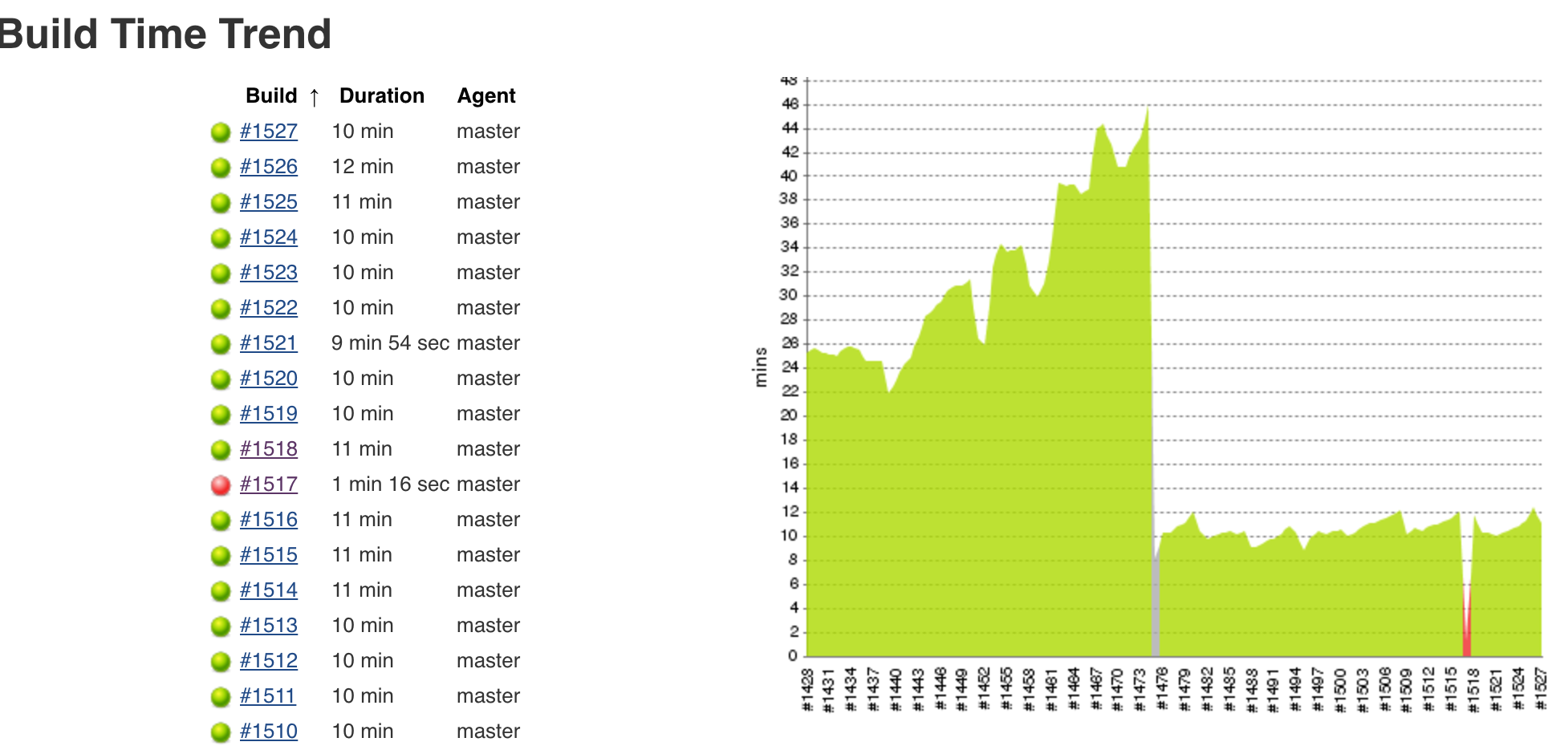
- is duplicated by
-
JENKINS-40099 Job creation takes awhile
-
- Closed
-
