-
New Feature
-
Resolution: Duplicate
-
 Minor
Minor
-
None
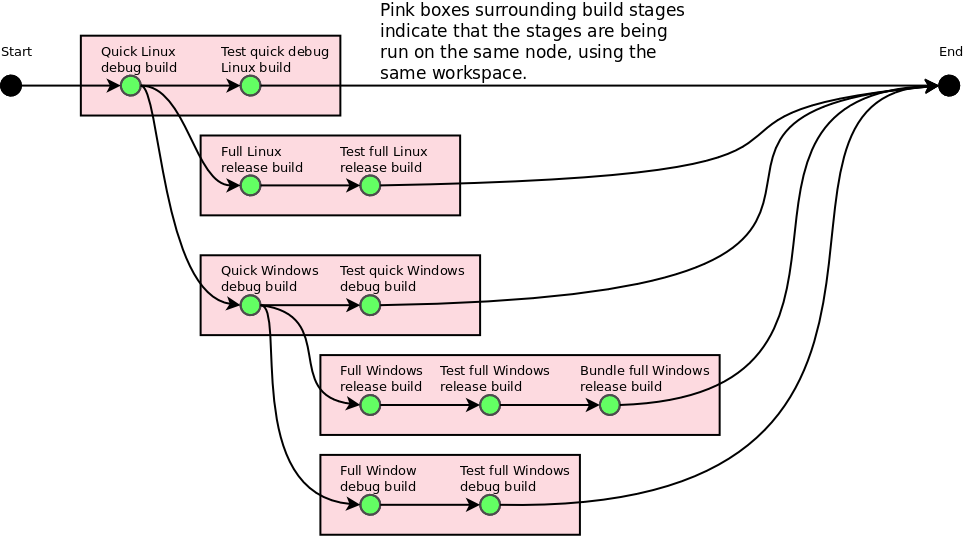
A question that always crops up when I try to introduce pipelines in my organisation, is how to use the same workspace across different stages that are run in sequence (but where the later stage may be joined by other stages that are being run in parallel). For example:
pipeline {
agent none
stages {
stage('first stage') { agent { label 'linux' } steps { ... } }
stage('parallel stage') {
parallel {
stage('second stage') { agent { label 'linux'} steps { ... } }
stage('other stage') { agent { label 'windows' } steps { ... } }
}
}
}
}
Here, we would like some way of representing that "second stage" should use the same node, and the same workspace, that was used for "first stage". They are both going to be run on a node labeled "linux", but we would like to force them to use the same node and even the same workspace. The last stage, called "other stage", is probably destined for a different type of node, since it is labeled differently. But it is important that "second stage" and "other stage" be able to run in parallel, if you decide to implement the feature we are requesting.
Our particular scenario is that we write a cross-platform C++ product, which has conceptually three phases - building, testing and bundling. The build directories are typically quite big, around 10-20 GB spread across the order of 50k-100k files. So stashing or uploading the interesting parts of the workspace as an artifact, and downloading them on another (or the same) node is not something we want to do.
Moreover, we wouldn't be comfortable doing this anyway, due to technicalities of what we do - there could be minor version differences in libraries on nodes, and there is the topic of debug symbols needing to match the code being executed. etc.
We have more than one node for each supported platform.
The current workaround is to put building, testing and bundling into the same stage. This has the following disadvantages:
- It doesn't make it possible to start building and testing in parallel on another platform as a consequence of just the build going well on the first platform.
- Feedback to developers about the state of the build is delayed until the tests have also had time to run (which can take some time).
- The typical visualization of the pipeline will not allow developers to discern the health of the build and test stages separately, since they will be illustrated together by a single node in the graph.
We would therefore like to request that the declarative pipeline syntax be extended to support some way of expressing that when a node matching some label is selected, it should be the same node as was selected in an earlier stage that used the same label, in the same pipeline.
Alternatively, the declarative pipeline syntax could have some way of assigning an identifier to the workspace used for the job at one stage in the pipeline, and some way of requiring that same workspace to be present at a later stage in the pipeline - effectively forcing it to be the same node as well.
See attachments for a simplified version of our current Jenkinsfile, and a diagram showing the kind of pipeline we would like to be make.
- duplicates
-
-
- Closed
-