-
New Feature
-
Resolution: Done
-
 Major
Major
-
-
Pipeline - October, Pipeline - December
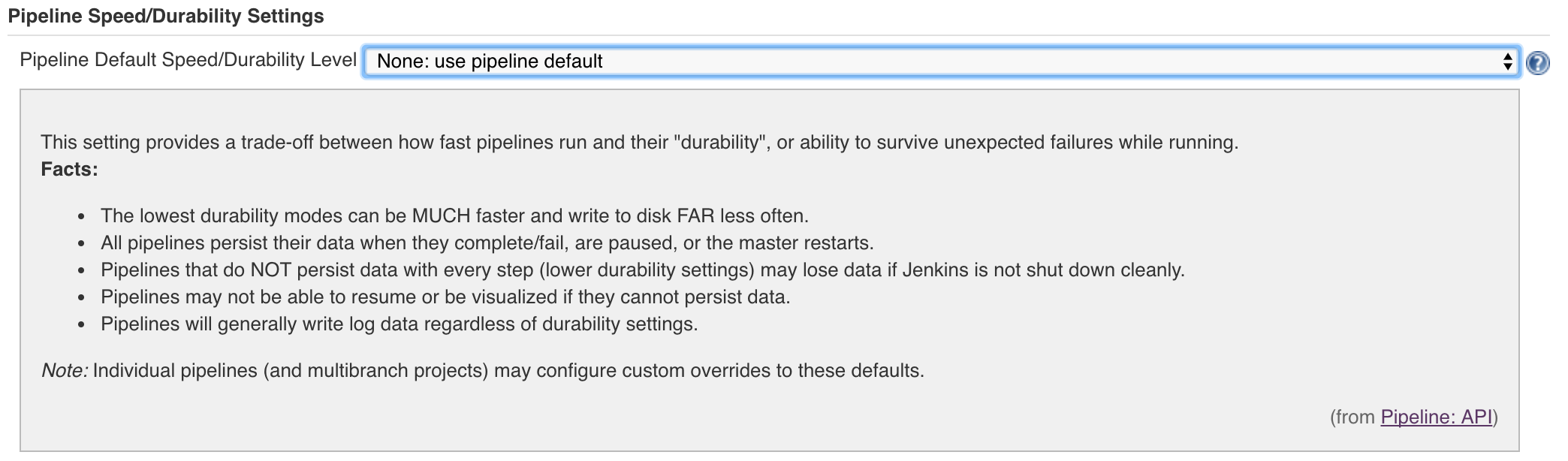
As a user of pipeline, I WANNA GO FAST. ![]()
To do that, I'm okay with sacrificing some of the ability to resume a pipeline after a hard Jenkins crash, as long as it means pipelines run fast. It would be nice if I can still resume the pipeline after a clean/safe restart of the master, though!
This differs from https://issues.jenkins-ci.org/browse/JENKINS-30896 because for this we're sacrificing some of the guarantees pipeline normally provides.
Concrete needs:
- Implement storage engine (workflow-support)
- Implement options to select that storage engine (workflow-job)
- Implement ability to RUN that storage engine (workflow-cps)
- is blocked by
-
JENKINS-47172 Provide more granular control of pipeline flownode persistence
-
- Closed
-
- is related to
-
JENKINS-30896 Unoptimized node storage
-
- Closed
-
-
-
- Closed
-
- relates to
-
-
- Closed
-
