-
Bug
-
Resolution: Fixed
-
 Blocker
Blocker
-
-
workflow-api 2.31
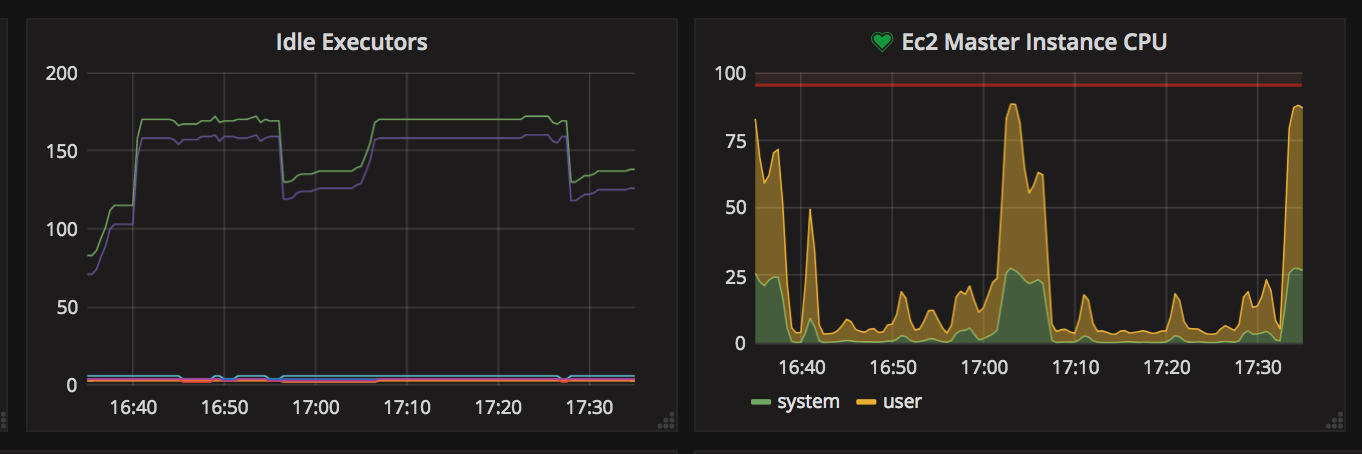
The graph here in this description more clearly depicts whats going on. I'm the only one using this jenkins server today...
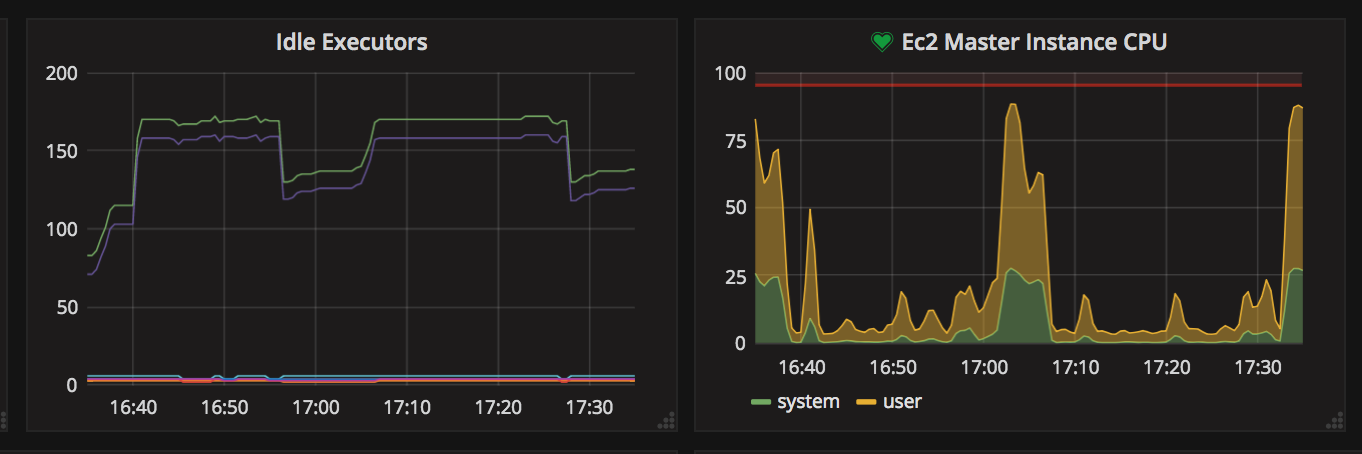
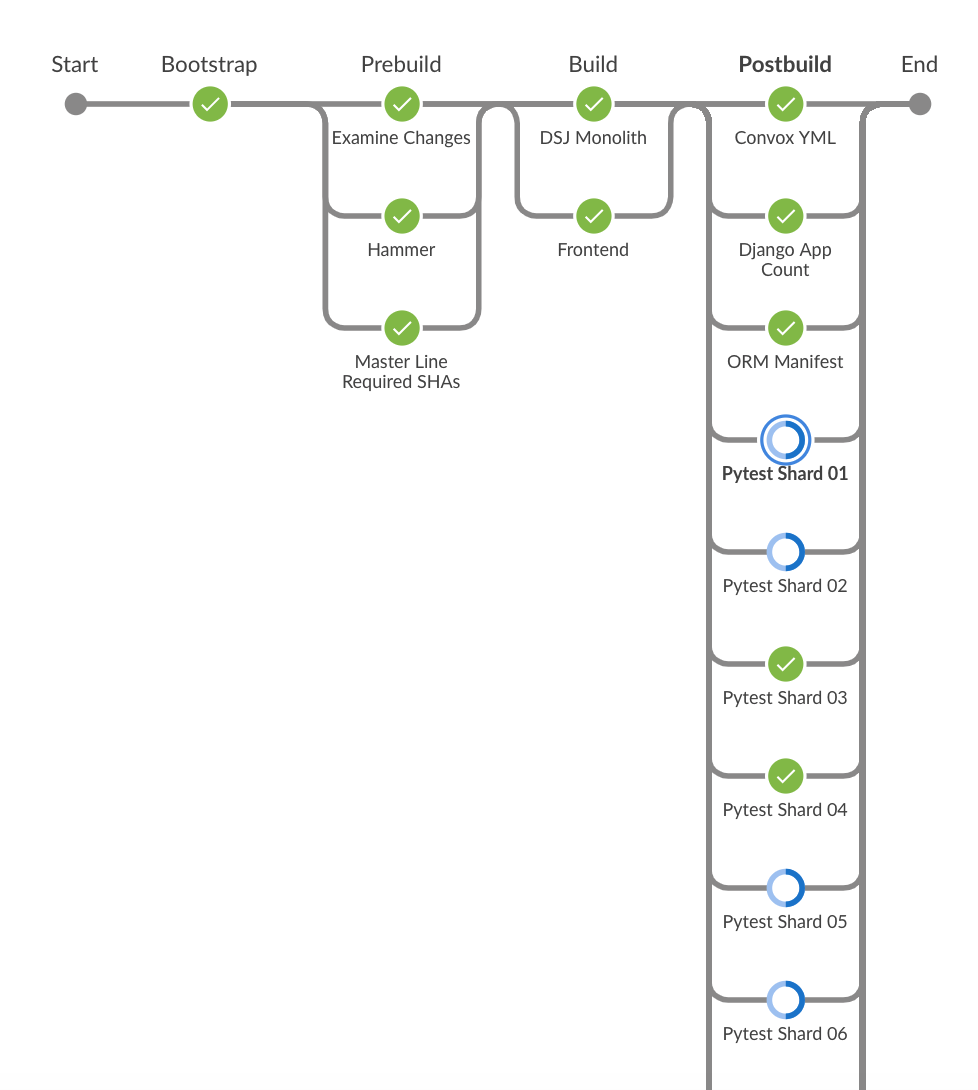
Around 5pm, i kicked off a pipeine. The pipeline builds a container and then uses that container to run some pytests...
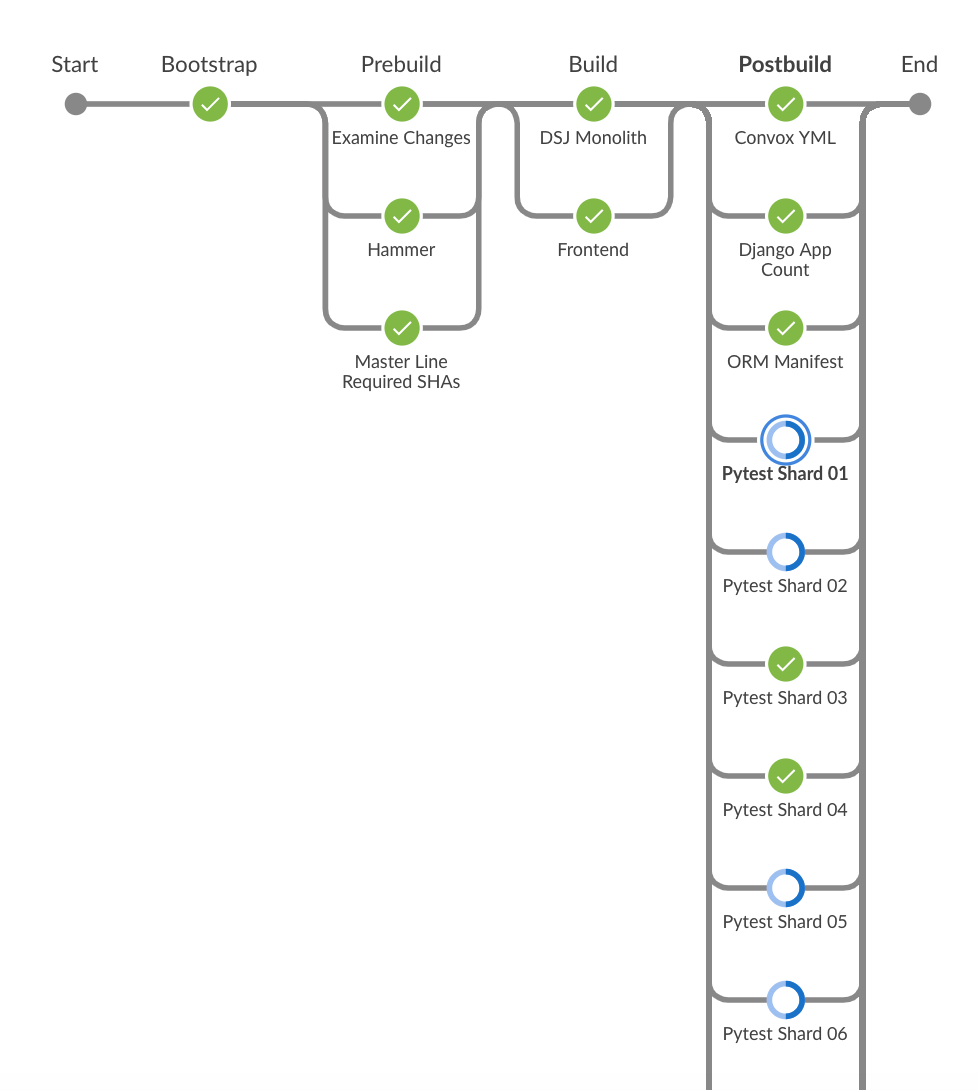
It is during that last "postbuild" phase, the CPU runs real hot. While the pytest shards are running, they are just doing a pytest run and then i capture the junit.xml file.
The reason why this is a problem is that with too many of these running at the same time, Jenkins blips out and we cannot contact the web interface because when the CPU is pegged.. it basically crashes the master.
Here are details about my jenkins:
My jenkins is 100% current:
- Jenkins ver. 2.147
- Please note I did today accept the plugin updates described on https://github.com/jenkinsci/jep/blob/master/jep/210/README.adoc#abstract


- relates to
-
-

- Resolved
-
-
JENKINS-38381 [JEP-210] Optimize log handling in Pipeline and Durable Task
-

- Resolved
-
-
JENKINS-56851 Flush durable task output before agent shutdown or before writing lastLocation
-
- Open
-
- links to
