-
Bug
-
Resolution: Unresolved
-
 Major
Major
-
Jenkins ver. 2.220
I have a pipeline project which should run at a EC2 instance node.
I have configured an EC2 connection and starting EC2 t3.medium Windows 10 instances automatically. This all works fine.
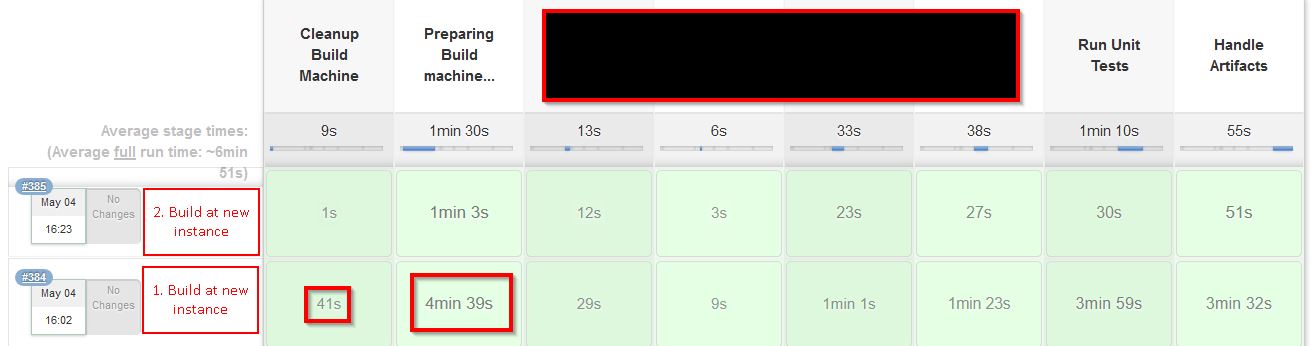
But, the first build at an EC2 instance always performs very bad (slow!!). The next build at the same instance (without rebott etc) is much more faster.
@Library('BMS-Libraries') import static bms.mail.Email.* import static bms.nexus.Nexus.* import static bms.utils.Utils.* node('AWS_VS2017') { stage('Cleanup Build Machine'){ //deleting current workspace directory deleteDir() } stage('Preparing Build machine...'){ retrieveAndExtractBuildTools(this) } //Do some more ....... }
I attached a screenshot of the runtime of the different pipeline steps.
I connected via RDP to the instance during first build nad task-manager didn't display a high CPU or Memory consumption