-
Bug
-
Resolution: Duplicate
-
 Critical
Critical
After running for 2-3 days, jenkins jobs no longer launch.
The console outputs usually just say that fetching from git failed, but sometimes contain other unusual errors.
The system log for jenkins reports
java.lang.OutOfMemoryError: unable to create new native thread
I was able to get a heap dump but due to the potential inclusion of sensitive data cannot post it.
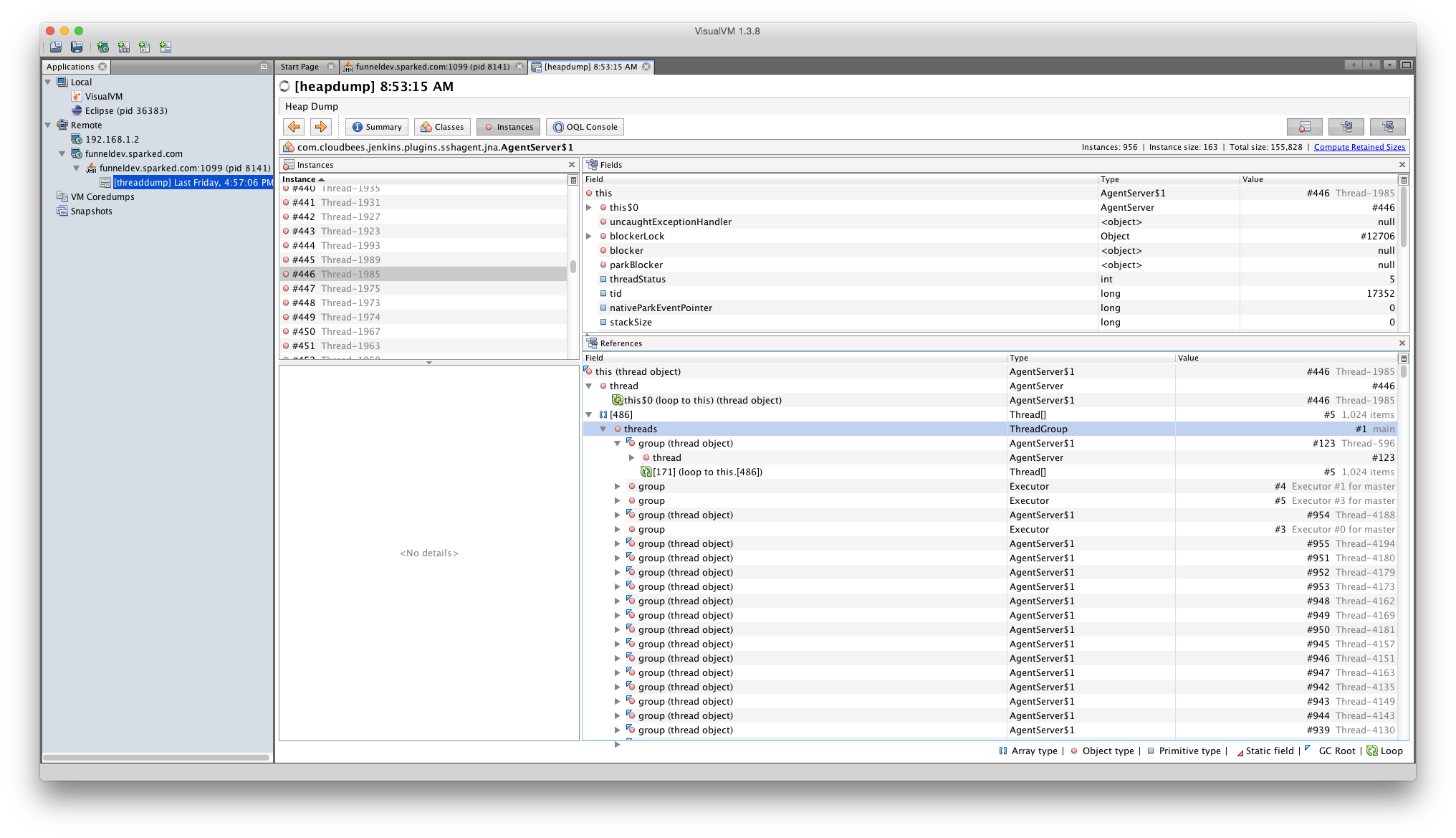
In VisualVM analysis of the heap dump, I noticed that there are almost 1000 instances of AgentServer and AgentServer$1. The threads don't show up in the thread monitor, but are still referenced somehow.
Unfortunately the parent references are numerous and hard to decipher. The proximate parent is the ThreadGroup.threads array in the main ThreadGroup instance. This seems unlikely to be the true root cause.
I also noticed about the same number of ThreadLocalMap instances, so the leak may be related to incorrect use of ThreadLocal.
Attached a screenshot of the AgentServer$1 instances in VisualVM, and the jenkins system log.
Please let me know if there is any other analysis I can provide.
I am entering this bug as blocker because I don't currently have a workaround. I am using jenkins in conjunction with an external php application that needs to post jobs to the jenkins build queue. Therefore, in order to workaround, I need to implement a controlled shutdown process and restart jenkins at a daily or semi-daily interval. This will ultimately require the calling application to retry, which is probably a good idea anyway, but is not yet implemented.
- duplicates
-
-

- Resolved
-