-
Improvement
-
Resolution: Fixed
-
 Major
Major
-
None
-
Jenkins 2.40
Blue Ocean 1.0.0-b17
This improvement is on the Blue Ocean project roadmap. Check the roadmap page for updates.
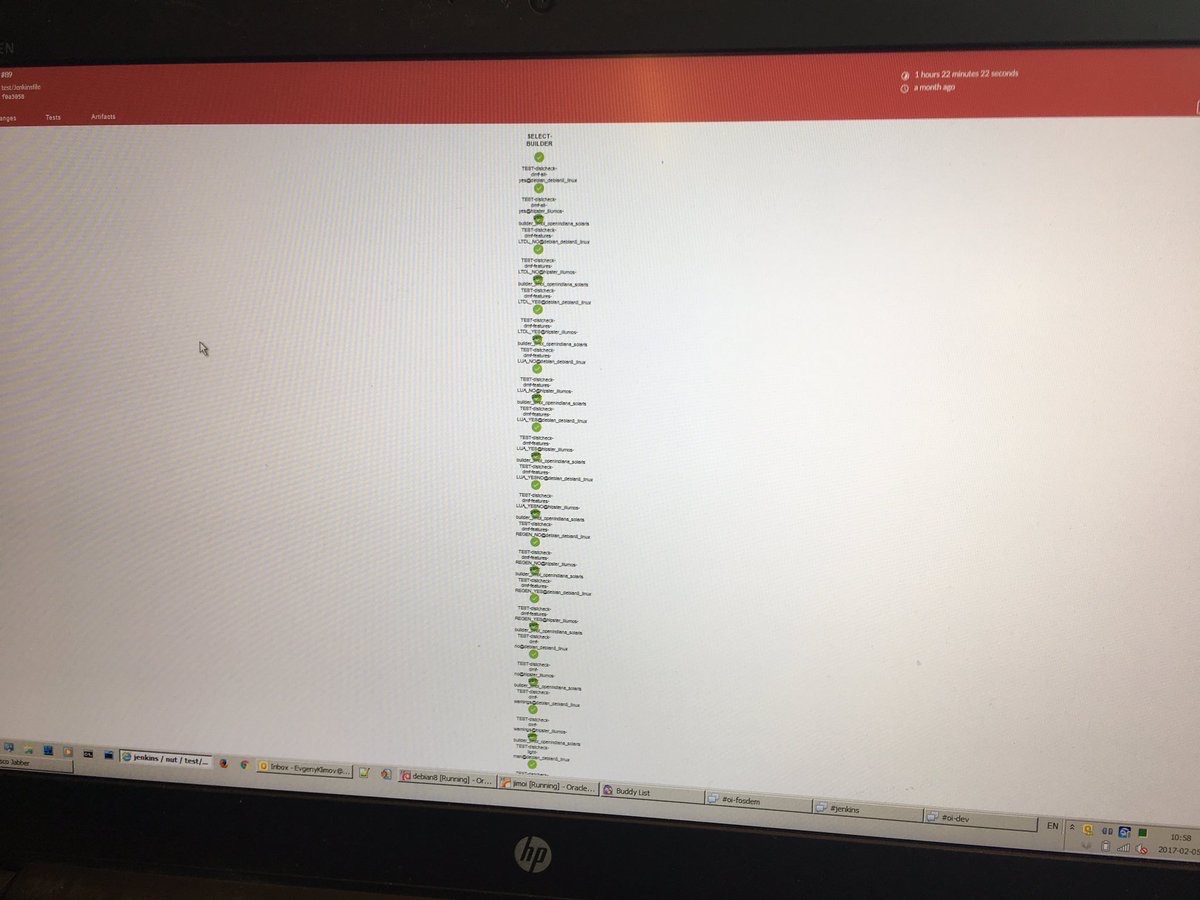
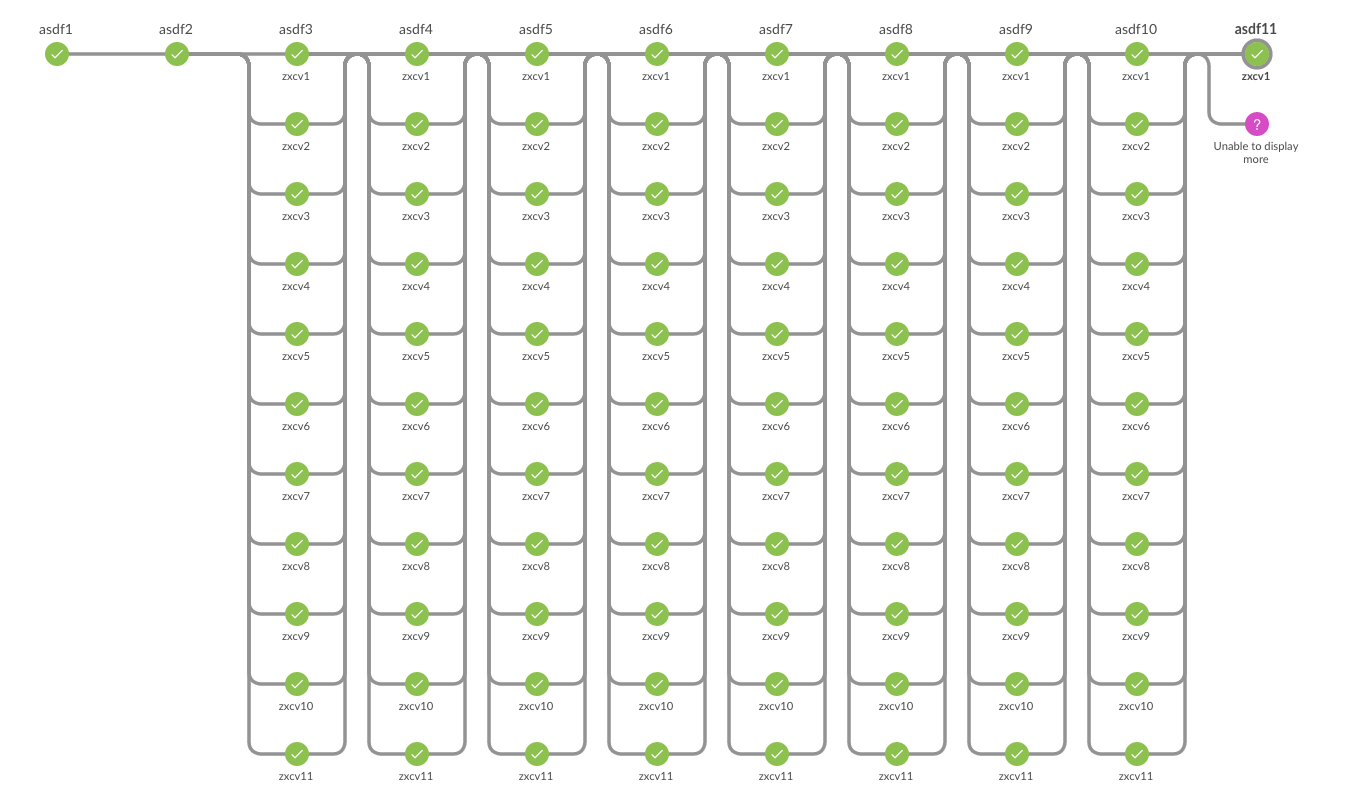
The Blue Ocean stage graph is great for small, simple pipelines however it breaks down with many parallel builds. See attached screenshot for an example.
Because 'stage' can no longer be nested within 'parallel', all of our steps must belong under a single 'Test' stage. We have 19 parallel jobs, which is not an uncommon number for iOS/Android development where many combinations of app, device and OS version need to be tested. We'd actually like to split some of the jobs into smaller chunks to take advantage of idle build agents, but this would greatly exacerbate the problem.
Grouping jobs under multiple stages would improve the UI experience, but also drastically increase the runtime of our integration runs as stages are executed serially.
I envision two possible solutions:
1. Stages have a 'parallel' option that allows them to run at the same time as other parallel stages.
2. A step is introduced that is used purely as an annotation for the purposes of rendering a more appropriate graph. Ideally the step would be deeply nestable allowing for complex graph hierarchies.
Thanks for all the hard work on Blue Ocean, it's really shaping up nicely and I eagerly await each new release.
- blocks
-
JENKINS-39770 Pipeline visualization not rendered when there is more that 100 nodes
-

- Reopened
-
- depends on
-
-
- Resolved
-
- is duplicated by
-
-
- Closed
-
-
JENKINS-46244 It would be nice to Paginate the steps within a node for Blue Ocean
-
- Resolved
-
- relates to
-
JENKINS-38442 View sequential stages in the pipeline visualization graph
-
- Closed
-
- links to
- mentioned in
-
Page Loading...

