-
New Feature
-
Resolution: Fixed
-
 Critical
Critical
-
None
While my pipeline was running, the node that was executing logic terminated. I see this at the bottom of my console output:
Cannot contact ip-172-31-242-8.us-west-2.compute.internal: java.io.IOException: remote file operation failed: /ebs/jenkins/workspace/common-pipelines-nodeploy at hudson.remoting.Channel@48503f20:ip-172-31-242-8.us-west-2.compute.internal: hudson.remoting.ChannelClosedException: Channel "unknown": Remote call on ip-172-31-242-8.us-west-2.compute.internal failed. The channel is closing down or has closed down
There's a spinning arrow below it.
I have a cron script that uses the Jenkins master CLI to remove nodes which have stopped responding. When I examine this node's page in my Jenkins website, it looks like the node is still running that job and i see an orange label that says "Feb 22, 2018 5:16:02 PM Node is being removed".
I'm wondering what would be a better way to say "If the channel closes down, retry the work on another node with the same label?
Things seem stuck. Please advise.
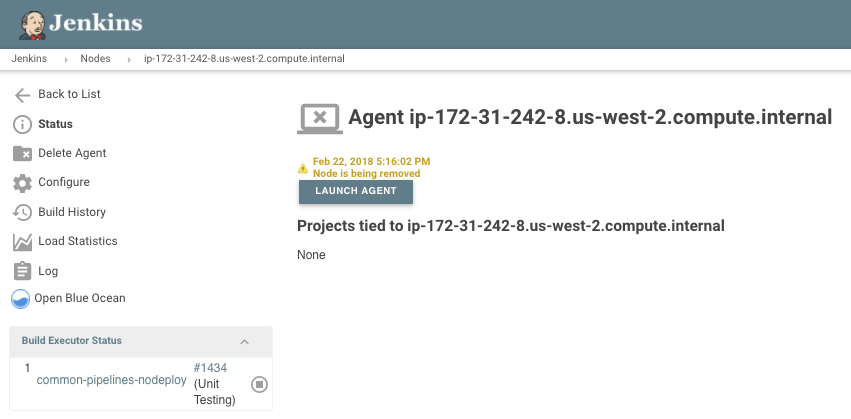



- causes
-
JENKINS-69936 PWD returning wrong path
-

- Resolved
-
-
-

- Resolved
-
- depends on
-
JENKINS-30383 SynchronousNonBlockingStepExecution should allow restart of idempotent steps
-
- Resolved
-
- is duplicated by
-
-
- Open
-
-
-
- Reopened
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Closed
-
-
-
- Resolved
-
-
-
- Resolved
-
- is related to
-
-
- Resolved
-
- relates to
-
-
- Closed
-
-
-
- Open
-
-
-
- Open
-
-
-
- Open
-
-
-
- Reopened
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Open
-
-
-
- Open
-
- links to
